Planar Maximally Filtered Graph (PMFG)
Note
The following sources elaborates extensively on the topic:
A planar graph is a graph which can be drawn on a flat surface without the edges crossing. The Planar Maximally Filtered Graph (PMFG) is a planar graph where the edges connecting the most similar elements are added first (Tumminello et al, 2005).
For example, for a correlation-based PMFG, the edges with the highest correlation would be added first. The steps to construct the PMFG are defined as follows:
-
Order the edges from the highest similarity to the lowest.
-
Add the edge with the highest similarity to the PMFG, if the resulting graph is planar
-
Keep adding edges from the ordered list, until \(3 (n - 2)\) edges have been added.
The PMFG retains the Minimum Spanning Tree (MST) as a subgraph, thus retains more information about the network than a MST (Tumminello et al, 2005).

PMFG example user interface.
PMFG contains \(3 (n - 2)\) edges as opposed to the MST, which contains \(n - 1\) edges for \(n\) number of nodes in the network.
PMFG
Background on Topology and Graph Theory
PMFG is the specific case where the graph is planar on genus \(k = 0\), which means the graph can be drawn on a flat surface without the edges crossing. However, the greater the genus, the greater the information stored in the graph. However, Tumminello et al (2005) state “major relative improvement” when the simplest graph is created of genus \(k = 0\), instead of for higher genus.
The figure shows three different shapes with different genera. A sphere in 2 dimensions is of genus \(k = 0\) (much like the PMFG). The torus is of genus \(k =1\) and the double torus of genus \(k = 2\) and so on. A coffee cup with a handle, would have the same topology as a torus.

Topological genera. From the left: Genus 0 (sphere), Genus 1 (torus), Genus 2 (double torus) (Warne, 2013).
The PMFG “is a topological triangulation of the sphere” (Tumminello et al, 2005).
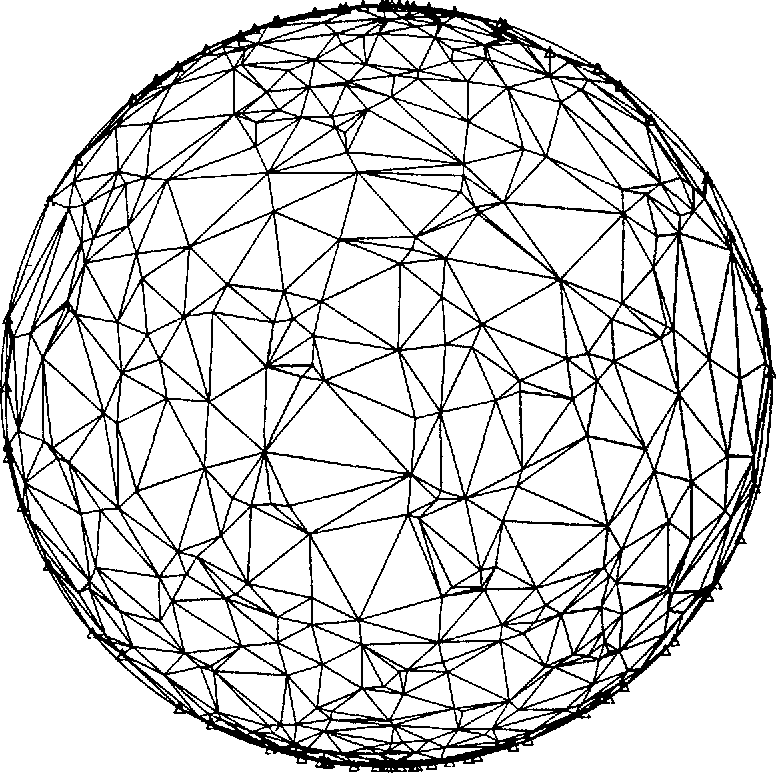
Example of a topological triangulation of a sphere (Renka, 1984).
Planar Graph Theory
According to Kuratowski’s theorem on planar graphs, a planar graph cannot contain a 5 clique (see \(k_{5}\) graph), nor can it contain a \(k_{3,3}\) bipartite graph where each node connects to every other node in the other group (see \(k_{3,3}\) graph) (Grünbaum and Bose, 2013).

Graph a) shows a 5 clique graph (\(k_{5}\)) and b) shows \(k_{3,3}\) bipartite graph (Staniec and Debita, 2012).
Only 3 cliques and 4 cliques are allowed in the PMFG. Cliques of higher orders are allowed if the genus is greater. For example, 5 cliques would be allowed in genus \(k = 1\). Analysing 3-cliques and 4-cliques can show the underlying hierarchical structure of the network and “have important and significant relations with the market structure and properties” (Aste et al, 2005).

An example of a 3 clique graph and a 4 clique graph.
Where \(k\) is the genus, and \(r\) is the number of elements, the number of elements allowed in a clique is given by Ringel (2012) as:
For example, for a graph of genus \(k = 1\), 5 cliques are allowed in the graph.
Analysing Cliques in PMFG
Analysis of 3-cliques and 4-cliques, describe the underlying hierarchical structure of the network and “have important and significant relations with the market structure and properties” (Aste et al, 2005). In the case of interest rates, the 4 cliques group together the rates with similar maturity dates (Aste et al, 2005). For stocks, 4-cliques tend to group with similar industry or sector groups (Tumminello et al, 2005). Therefore, 3-cliques and 4-cliques can be useful to analyse and understand the network.
Tumminello et al (2005) proposes a measure of disparity \(y_{i}\) defined as follows:
The mean value of the disparity measure is the sum of \(y_{i}\) divided by the number of nodes in the clique. The strength of an element \(s_{i}\) is calculated by:
The disparity measure is only meaningful if all of the edges in the clique have a correlation value of 0 or greater, which is why some disparity measure values may be excessively large.
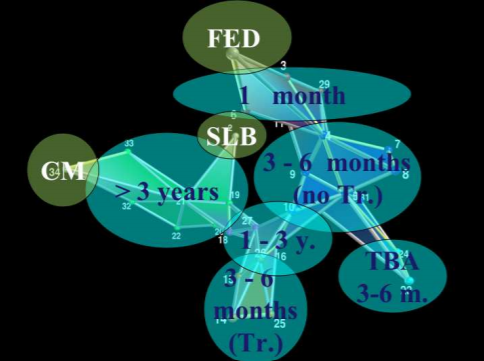
PMFG 34 US interest rates, with 4 cliques highlighted (Aste et al, 2005).
Aste et al (2005) found that the groups of 4-cliques “reveal the hierarchical organization of the underlying system… grouping together the interest rates with similar maturity dates”. The figure above is an example of how the cliques form according to the maturity dates.
The average disparity measure for all 3 cliques and 4 cliques are shown in the PMFG interface under the statistic name disparity_measure.
Creating the PMFG
You can create the PMFG visualisation using generate_pmfg_server. This requires you to input a log returns dataframe.
# Import pandas
import pandas as pd
# Import generate_pmfg_server method
from mlfinlab.networks.visualisations import generate_pmfg_server
# Import log return csv
url = "https://raw.githubusercontent.com/hudson-and-thames/example-data/main/logReturns.csv"
# Need to make sure all other columns are removed and leave numerical data only
log_return_dataframe = pd.read_csv(url, index_col='Date')
# Create a smaller sample for testing
log_return_dataframe = log_return_dataframe.loc[:, ['NVDA', 'TWTR', 'MSFT', 'JNJ', 'TSLA', 'GE']]
# Creates the PMFG comparison server
server = generate_pmfg_server(log_return_dataframe)
# Run the server in the command line
server.run_server()
Note
Log returns dataframe should be calculated as \(log P_{i}(t) - log P_{i}(t-1)\) for asset \(i\) and price \(P\).
Implementation
Here are the options you can use for the generate_pmfg_server:
- generate_pmfg_server(log_returns_df, input_type='distance', jupyter=False, colours=None, sizes=None)
-
This method returns a PMFGDash server ready to be run.
- Parameters:
-
-
log_returns_df – (pd.DataFrame) An input dataframe of log returns with stock names as columns.
-
input_type – (str) A valid input type correlation or distance. Inputting correlation will add the edges by largest to smallest, instead of smallest to largest.
-
jupyter – (bool) True if the user would like to run inside jupyter notebook. False otherwise.
-
colours – (Dict) A dictionary of key string for category name and value of a list of indexes corresponding to the node indexes inputted in the initial dataframe.
-
sizes – (List) A list of numbers, where the positions correspond to the node indexes inputted in the initial dataframe.
-
- Returns:
-
(Dash) Returns the Dash app object, which can be run using run_server. Returns a Jupyter Dash object if the parameter jupyter is set to True.
Specifying “correlation” instead of the default “distance”, the PMFG algorithm orders the edges from largest to smallest edge instead of the other way round. The optional format for the colours and sizes, can be specified in the following manner:
# Optional - add industry groups for node colour
industry = {"tech": ['NVDA', 'TWTR', 'MSFT'], "utilities": ['JNJ'], "automobiles": ['TSLA', 'GE']}
# Optional - adding market cap for node size, corresponding to node input index.
market_caps = [2000, 2500, 3000, 1000, 5000, 3500]
# Creates the PMFG comparison server
server = generate_pmfg_server(log_return_dataframe, colours=industry, sizes=market_caps)

The MST edges, contained within the PMFG, are displayed in green.
Custom Input Matrix PMFG
As is the case for MST and ALMST, to input a custom matrix, you must create a PMFG class directly. This gives you the option to transform the input dataframe directly, instead of a log returns dataframe, allowing you to make specific transformations instead of the default way to create “correlation” or “distance” matrix. However, PMFG only allows input_type of “correlation” or “distance” to specify whether the PMFG algorithm should add the edges from largest to smallest or smallest to largest respectively.
# Import pandas
import pandas as pd
# Import PMFG class
from mlfinlab.networks.pmfg import PMFG
# Import PMFG Dash Graph class
from mlfinlab.networks.dash_graph import DashGraph
# Import log return csv
url = "https://raw.githubusercontent.com/hudson-and-thames/example-data/main/logReturns.csv"
# Need to make sure all other columns are removed and leave numerical data only
log_return_dataframe = pd.read_csv(url, index_col='Date')
# Create a smaller sample for testing
log_return_dataframe = log_return_dataframe.loc[:, ['NVDA', 'TWTR', 'MSFT', 'JNJ', 'TSLA', 'GE']]
# Create your custom matrix
custom_matrix = log_return_dataframe.corr(method='pearson')
# Input ‘correlation’ as matrix type, to order the PMFG algorithm from largest to smallest
graph = PMFG(custom_matrix, 'correlation')
# Create and get the server
dash_graph = DashGraph(graph)
server = dash_graph.get_server()
# Run server
server.run_server()
Once the PMFG class object has been created, you can set the colours and sizes properties of the graph.
Adding Colours to Nodes
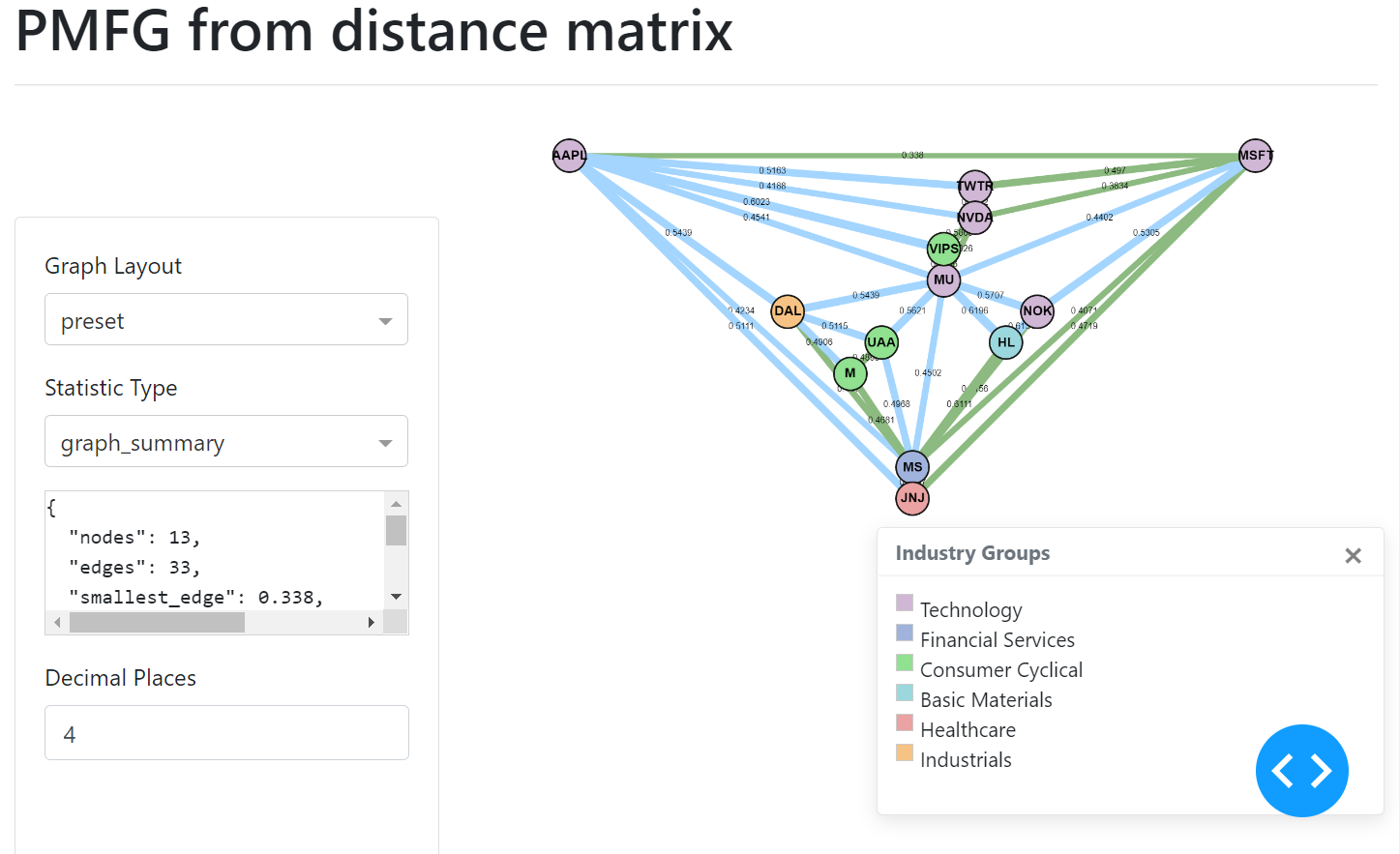
The colours can be added by passing a dictionary of group name to list of node names corresponding to the nodes input. You then pass the dictionary to the set_node_groups method.
# Optional - add industry groups for node colour
industry = {"tech": ['NVDA', 'TWTR', 'MSFT'], "utilities": ['JNJ'], "automobiles": ['TSLA', 'GE']}
graph.set_node_groups(industry)
Adding Sizes to Nodes
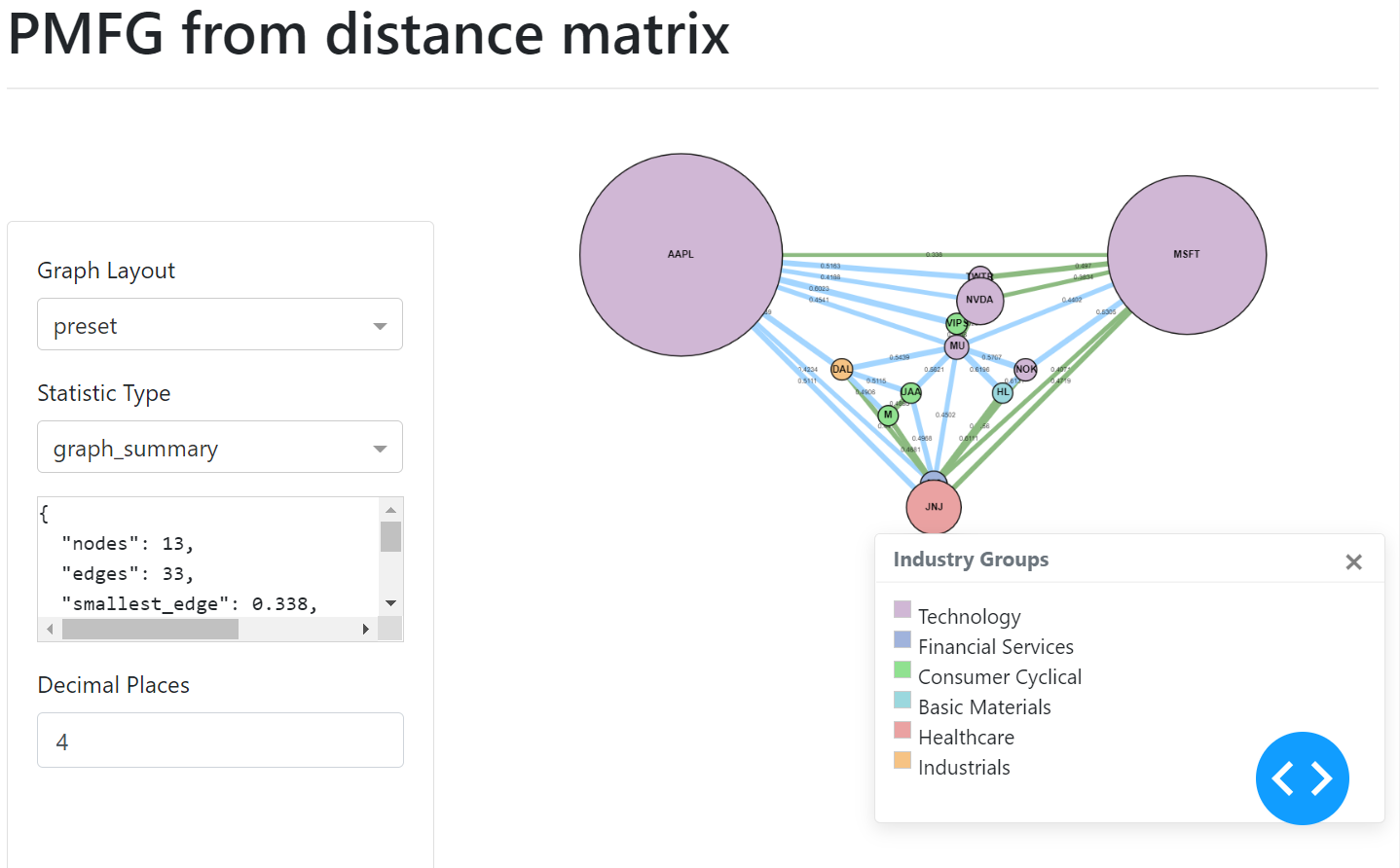
The sizes can be added in a similar manner, via a list of numbers which correspond to the node indexes. The UI of the graph will then display the nodes indicating the different sizes.
# Optional - adding market cap for node size
market_caps = [2000, 2500, 3000, 1000, 5000, 3500]
graph.set_node_size(market_caps)
The PMFG object, once constructed, serves as the input to the PMFGDash class. To run the PMFGDash within the Jupyter notebook, make sure to pass in the parameter.
server = PMFGDash(pmfg, app_display=’jupyter notebook')
Where calling get_server will return the Dash server with the frontend components. Then you can call:
server.run_server()
Which is the default option, or alternatively for Jupyter dash, specify the mode as ‘inline’, ‘external’ or ‘jupyterlab’. The ‘external’ mode is very useful for larger graphs, as you can view the PMFG in a new window.
server.run_server(mode=’inline’)

PMFG Class
- class PMFG(input_matrix, matrix_type)
-
PMFG class creates and stores the PMFG as an attribute.
- __init__(input_matrix, matrix_type)
-
PMFG class creates the Planar Maximally Filtered Graph and stores it as an attribute.
- Parameters:
-
-
input_matrix – (pd.DataFrame) Input distance matrix
-
matrix_type – (str) Matrix type name (e.g. “distance”).
-
- __weakref__
-
list of weak references to the object (if defined)
- create_pmfg(input_matrix)
-
Creates the PMFG matrix from the input matrix of all edges.
- Parameters:
-
input_matrix – (pd.DataFrame) Input matrix with all edges
- Returns:
-
(nx.Graph) Output PMFG matrix
- edge_in_mst(node1, node2)
-
Checks whether the edge from node1 to node2 is a part of the MST.
- Parameters:
-
-
node1 – (str) Name of the first node in the edge.
-
node2 – (str) Name of the second node in the edge.
-
- Returns:
-
(bool) Returns true if the edge is in the MST. False otherwise.
- get_difference(input_graph_two)
-
Given two Graph with the same nodes, return a set of differences in edge connections.
- Parameters:
-
input_graph_two – (Graph) A graph to compare self.graph against.
- Returns:
-
(List) A list of unique tuples showing different edge connections.
- get_disparity_measure()
-
Getter method for the dictionary of disparity measure values of cliques.
- Returns:
-
(Dict) Returns a dictionary of clique to the disparity measure.
- get_graph()
-
Returns the Graph stored as an attribute.
- Returns:
-
(nx.Graph) Returns a NetworkX graph object.
- get_graph_plot()
-
Overrides parent get_graph_plot to plot it in a planar format.
Returns the graph of the MST with labels. Assumes that the matrix contains stock names as headers.
- Returns:
-
(AxesSubplot) Axes with graph plot. Call plt.show() to display this graph.
- get_matrix_type()
-
Returns the matrix type set at initialisation.
- Returns:
-
(str) String of matrix type (eg. “correlation” or “distance”).
- get_mst_edges()
-
Returns the list of MST edges.
- Returns:
-
(list) Returns a list of tuples of edges.
- get_node_colours()
-
Returns a map of industry group matched with list of nodes.
- Returns:
-
(Dict) Dictionary of industry name to list of node indexes.
- get_node_sizes()
-
Returns the node sizes as a list.
- Returns:
-
(List) List of numbers representing node sizes.
- get_pos()
-
Returns the dictionary of the nodes coordinates.
- Returns:
-
(Dict) Dictionary of node coordinates.
- set_node_groups(industry_groups)
-
Sets the node industry group, by taking in a dictionary of industry group to a list of node indexes.
- Parameters:
-
industry_groups – (Dict) Dictionary of the industry name to a list of node indexes.
- set_node_size(market_caps)
-
Sets the node sizes, given a list of market cap values corresponding to node indexes.
- Parameters:
-
market_caps – (List) List of numbers corresponding to node indexes.
PMFGDash Class
- class PMFGDash(input_graph, app_display='default')
-
PMFGDash class, a child of DashGraph, is the Dash interface class to display the PMFG.
- __init__(input_graph, app_display='default')
-
Initialise the PMFGDash class but override the layout options.
- __weakref__
-
list of weak references to the object (if defined)
- get_graph_summary()
-
Returns the Graph Summary statistics. The following statistics are included - the number of nodes and edges, smallest and largest edge, average node connectivity, normalised tree length and the average shortest path.
- Returns:
-
(Dict) Dictionary of graph summary statistics.
- get_server()
-
Returns a small Flask server.
- Returns:
-
(Dash) Returns the Dash app object, which can be run using run_server. Returns a Jupyter Dash object if DashGraph has been initialised for Jupyter Notebook.
Research Notebook
The following notebook provides a more detailed exploration of the PMFG creation.
PMFG visualisation