Purged and Embargo
This implementation is based on Chapter 7 of the book Advances in Financial Machine Learning.
The purpose of performing cross validation is to reduce the probability of over-fitting and the book recommends it as the main tool of research. There are two innovations compared to the classical K-Fold Cross Validation implemented in sklearn.
-
The first one is a process called purging which removes from the training set those samples that are build with information that overlaps samples in the testing set. More details on this in section 7.4.1, page 105.

Image showing the process of purging. Figure taken from page 107 of the book.
2. The second innovation is a process called embargo which removes a number of observations from the end of the test set. This further prevents leakage where the purging process is not enough. More details on this in section 7.4.2, page 107.
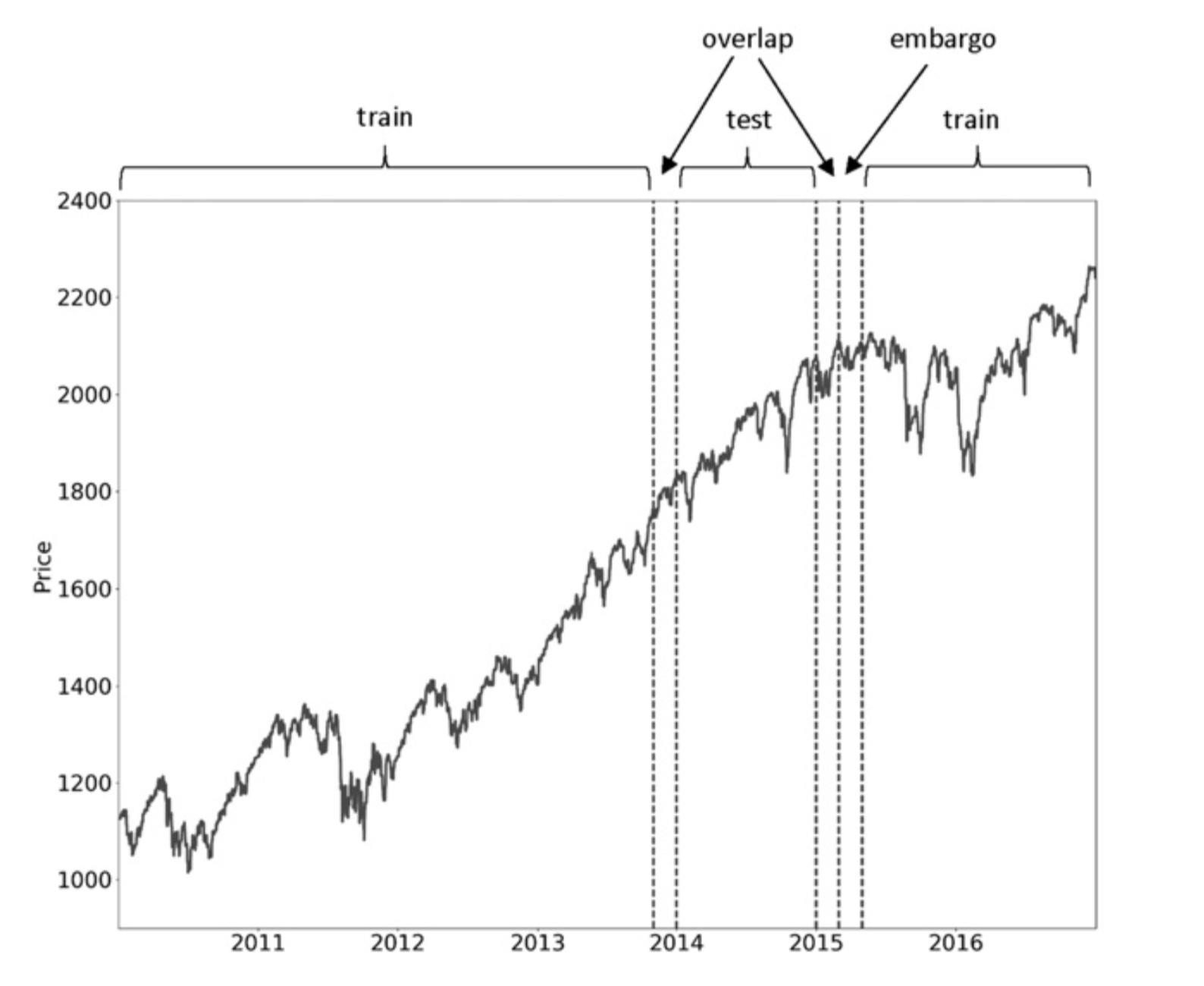
Image showing the process of embargo. Figure taken from page 108 of the book.
A version of Purged K-Fold Cross Validation is also available for multi-asset (stacked) datasets.
Implementation
- ml_get_train_times(samples_info_sets: Series, test_times: Series) Series
-
Advances in Financial Machine Learning, Snippet 7.1, page 106.
Purging observations in the training set.
This function find the training set indexes given the information on which each record is based and the range for the test set. Given test_times, find the times of the training observations.
- Parameters:
-
-
samples_info_sets – (pd.Series) The information range on which each record is constructed from samples_info_sets.index: Time when the information extraction started. samples_info_sets.value: Time when the information extraction ended.
-
test_times – (pd.Series) Times for the test dataset.
-
- Returns:
-
(pd.Series) Training set.
- class PurgedKFold(n_splits: int = 3, samples_info_sets: Series | None = None, pct_embargo: float = 0.0)
-
Extend KFold class to work with labels that span intervals.
The train is purged of observations overlapping test-label intervals. Test set is assumed contiguous (shuffle=False), w/o training samples in between.
- __init__(n_splits: int = 3, samples_info_sets: Series | None = None, pct_embargo: float = 0.0)
-
Initialize.
- Parameters:
-
-
n_splits – (int) The number of splits. Default to 3
-
samples_info_sets – (pd.Series) The information range on which each record is constructed from samples_info_sets.index: Time when the information extraction started. samples_info_sets.value: Time when the information extraction ended.
-
pct_embargo – (float) Percent that determines the embargo size.
-
- split(X: DataFrame, y: Series | None = None, groups=None) tuple
-
The main method to call for the PurgedKFold class.
- Parameters:
-
-
X – (pd.DataFrame) Samples dataset that is to be split.
-
y – (pd.Series) Sample labels series.
-
groups – (array-like), with shape (n_samples,), optional Group labels for the samples used while splitting the dataset into train/test set.
-
- Returns:
-
(tuple) [train list of sample indices, and test list of sample indices].
- ml_cross_val_score(classifier: ~sklearn.base.ClassifierMixin, X: ~pandas.core.frame.DataFrame, y: ~pandas.core.series.Series, cv_gen: ~sklearn.model_selection._split.BaseCrossValidator, require_proba: bool, sample_weight_train: ~numpy.ndarray | None = None, sample_weight_score: ~numpy.ndarray | None = None, scoring: ~typing.Callable[[~numpy.array, ~numpy.array], float] = <function log_loss>, n_jobs_score: int = 1) array
-
Advances in Financial Machine Learning, Snippet 7.4, page 110. Using the PurgedKFold Class.
Function to run a cross-validation evaluation of the using sample weights and a custom CV generator. Note: This function is different to the book in that it requires the user to pass through a CV object. The book will accept a None value as a default and then resort to using PurgedCV, this also meant that extra arguments had to be passed to the function. To correct this we have removed the default and require the user to pass a CV object to the function.
Example:
cv_gen = PurgedKFold( n_splits=n_splits, samples_info_sets=samples_info_sets, pct_embargo=pct_embargo ) scores_array = ml_cross_val_score( classifier, X, y, cv_gen, require_proba, sample_weight_train=sample_train, sample_weight_score=sample_score, scoring=accuracy_score, )
- Parameters:
-
-
classifier – (ClassifierMixin) A sk-learn Classifier object instance.
-
X – (pd.DataFrame) The dataset of records to evaluate.
-
y – (pd.Series) The labels corresponding to the X dataset.
-
cv_gen – (BaseCrossValidator) Cross Validation generator object instance.
-
require_proba – (bool) Boolean flag that indicates whether the scoring function requires probabilities as input. Set to
Trueifscoringrequires probabilities as input. Set toFalseifscoringrequires predictions as input. -
sample_weight_train – (np.array) Sample weights used to train the model for each record in the dataset.
-
sample_weight_score – (np.array) Sample weights used to evaluate the model quality.
-
scoring – (Callable) A metric scoring, can be custom sklearn metric. Default value is sklearn.metrics.log_loss.
-
n_jobs_score – (int) Number of cores used in score function calculation.
-
- Returns:
-
(np.array) The computed score.
- class MultiAssetPurgedKFold(n_splits: int = 3, samples_info_sets: Series | None = None, pct_embargo: float = 0.0)
-
Extend KFold class to work with labels that span intervals for multi-asset(stacked) datasets.
The train is purged of observations overlapping test-label intervals. Test set is assumed contiguous (shuffle=False), w/o training samples in between.
- __init__(n_splits: int = 3, samples_info_sets: Series | None = None, pct_embargo: float = 0.0)
-
Initialize.
- Parameters:
-
-
n_splits – (int) The number of splits. Default to 3
-
samples_info_sets – (pd.Series) The information range on which each record is constructed from samples_info_sets.index: Time when the information extraction started. samples_info_sets.value: Time when the information extraction ended.
-
pct_embargo – (float) Percent that determines the embargo size.
-
- split(X: DataFrame, y: Series | None = None, groups: Series | None = None) tuple
-
The main method to call for the MultiAssetPurgedKFold class.
- Parameters:
-
-
X – (pd.DataFrame) Samples dataset that is to be split.
-
y – (pd.Series) Sample ranking series.
-
groups – (pd.Series) Deprecated parameter, using samples_info_sets as groups.
-
- Returns:
-
(tuple) [train list of sample indices, and test list of sample indices].
Research Notebook
Chapter 9 Hyperparameter Tuning with CV
Chapter 7 Cross-Validation Questions
Presentation Slides

Note
These slides are a collection of lectures so you need to do a bit of scrolling to find the correct sections.
pg 14-18: CV in Finance
pg 30-34: Hyper-parameter Tuning with CV
pg 122-126: Cross-Validation