Combinatorial Purged CV (CPCV)
This implementation is based on Chapter 12 of the book Advances in Financial Machine Learning.
Given a number \(φ\) of backtest paths targeted by the researcher, CPCV generates the precise number of combinations of training/testing sets needed to generate those paths, while purging training observations that contain leaked information.
Note
CPCV can be used for both for cross-validation and backtesting. Instead of backtesting using single path, the researcher may use CPCV to generate various train/test splits resulting in various paths.
CPCV algorithm for backtesting a machine learning model:
Partition \(T\) observations into \(N\) groups without shuffling, where groups \(n = 1, ... , N − 1\) are of size \([T∕N]\), and the \(N\) -th group is of size \(T − [T∕N] (N − 1)\).
Compute all possible training/testing splits, where for each split \(N − k\) groups constitute the training set and \(k\) groups constitute the testing set.
For any pair of labels \((y_i , y_j)\), where \(y_i\) belongs to the training set and \(y_j\) belongs to the testing set, apply the PurgedKFold class to purge \(y_i\) if \(y_i\) spans over a period used to determine label \(y_j\) . This class will also apply an embargo, should some testing samples predate some training samples.
Fit classifiers \(( N )\) on the \(N−k\) training sets, and produce forecasts on the respective \(N−k\) testing sets.
Compute the \(φ [N, k]\) backtest paths. You can calculate one Sharpe ratio from each path, and from that derive the empirical distribution of the strategy’s Sharpe ratio (rather than a single Sharpe ratio, like WF or CV).
When combinatorial splits were generated, CombinatorialPurgedKFold class contains backtest paths formed from train/test splits.
Note
In MlFinLab, CombinatorialPurgedKFold class can be used for both cross-validation (using split function call) and backtesting - using the generate_cpcv_backtest_paths_models method.
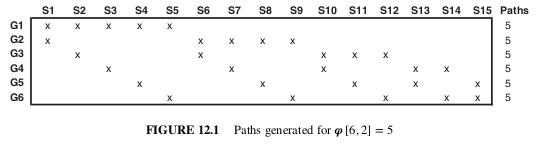
Image showing splits for CPCV(6,2)
A version of Combinatorial Purged K-Fold Cross Validation is also available for multi-asset (stacked) datasets.
Implementation
- ml_get_train_times(samples_info_sets: Series, test_times: Series) Series
-
Advances in Financial Machine Learning, Snippet 7.1, page 106.
Purging observations in the training set.
This function find the training set indexes given the information on which each record is based and the range for the test set. Given test_times, find the times of the training observations.
- Parameters:
-
-
samples_info_sets – (pd.Series) The information range on which each record is constructed from samples_info_sets.index: Time when the information extraction started. samples_info_sets.value: Time when the information extraction ended.
-
test_times – (pd.Series) Times for the test dataset.
-
- Returns:
-
(pd.Series) Training set.
- class CombinatorialPurgedKFold(n_splits: int = 3, n_test_splits: int = 2, samples_info_sets: Series | None = None, pct_embargo: float = 0.0)
-
Advances in Financial Machine Learning, Chapter 12.
Implements Combinatorial Purged Cross Validation (CPCV).
The train is purged of observations overlapping test-label intervals. Test set is assumed contiguous (shuffle=False), w/o training samples in between.
- __init__(n_splits: int = 3, n_test_splits: int = 2, samples_info_sets: Series | None = None, pct_embargo: float = 0.0)
-
Initialize.
- Parameters:
-
-
n_splits – (int) The number of splits. Default to 3
-
samples_info_sets – (pd.Series) The information range on which each record is constructed from samples_info_sets.index: Time when the information extraction started. samples_info_sets.value: Time when the information extraction ended.
-
pct_embargo – (float) Percent that determines the embargo size.
-
- generate_cpcv_backtest_paths_models(model: object, X: DataFrame, y: Series, sample_weight_train: ndarray | None = None) list
-
This function generates a list of CPCV backtest paths under current CPCV(k, n) scheme. Each list consists of dictionary with a string (<start date>_<end date> when model should be used) and corresponding fit model.
- Parameters:
-
-
model – (object) Unfit classifier or regressor model.
-
X – (pd.DataFrame) Samples dataset that is to be split.
-
y – (pd.Series) Sample labels series.
-
sample_weight_train – (np.ndarray) Sample weights.
-
- Returns:
-
(list) List of backtest paths.
- split(X: DataFrame, y: Series | None = None, groups=None) tuple
-
The main method to call for the PurgedKFold class.
- Parameters:
-
-
X – (pd.DataFrame) Samples dataset that is to be split.
-
y – (pd.Series) Sample labels series.
-
groups – (array-like), with shape (n_samples,), optional Group labels for the samples used while splitting the dataset into train/test set.
-
- Returns:
-
(tuple) [train list of sample indices, and test list of sample indices].
- class MultiAssetCombinatorialPurgedKFold(n_splits: int = 3, n_test_splits: int = 2, samples_info_sets: Series | None = None, pct_embargo: float = 0.0)
-
Implements Combinatorial Purged Cross Validation class (CPCV) to work with labels that span intervals for multi-asset datasets.
The train is purged of observations overlapping test-label intervals. Test set is assumed contiguous (shuffle=False), w/o training samples in between.
- __init__(n_splits: int = 3, n_test_splits: int = 2, samples_info_sets: Series | None = None, pct_embargo: float = 0.0)
-
Initialize.
- Parameters:
-
-
n_splits – (int) The number of splits. Default to 3
-
n_test_splits – (int) The number of test folds. Default to 2
-
samples_info_sets – (pd.Series) The information range on which each record is constructed from samples_info_sets.index: Time when the information extraction started. samples_info_sets.value: Time when the information extraction ended.
-
pct_embargo – (float) Percent that determines the embargo size.
-
- get_folds_splits(combinatorial_groups_splits: list) list
-
Find train and test folds for backtest_paths.
The example input for KFold (4, 2) looks like: [(2, 3), (1, 3), (1, 2), (0, 3), (0, 2), (0, 1)]
The output looks like: [[{‘train’: array([2, 3]), ‘test’: 0},{‘train’: array([2, 3]), ‘test’: 1}, {‘train’: array([1, 3]), ‘test’: 2},{‘train’: array([1, 2]), ‘test’: 3}], [{‘train’: array([1, 3]), ‘test’: 0},{‘train’: array([0, 3]), ‘test’: 1}, {‘train’: array([1, 3]), ‘test’: 2},{‘train’: array([1, 2]), ‘test’: 3}], [{‘train’: array([1, 2]), ‘test’: 0}, {‘train’: array([0, 2]), ‘test’: 1}, {‘train’: array([0, 1]), ‘test’: 2}, {‘train’: array([1, 2]), ‘test’: 3}], [{‘train’: array([1, 3]), ‘test’: 0}, {‘train’: array([0, 3]), ‘test’: 1}, {‘train’: array([0, 3]), ‘test’: 2}, {‘train’: array([0, 2]), ‘test’: 3}], [{‘train’: array([1, 2]), ‘test’: 0}, {‘train’: array([0, 2]), ‘test’: 1}, {‘train’: array([0, 1]), ‘test’: 2}, {‘train’: array([0, 2]), ‘test’: 3}], [{‘train’: array([1, 2]), ‘test’: 0}, {‘train’: array([0, 2]), ‘test’: 1}, {‘train’: array([0, 1]), ‘test’: 2}, {‘train’: array([0, 1]), ‘test’: 3}]]
- Parameters:
-
combinatorial_groups_splits – (list) Tuples with train folds splits.
- Returns:
-
(list) Lists of dictionaries of all train/test splits for each fold.
- split(X: DataFrame, y: Series | None = None, groups: Series | None = None) tuple
-
The main method to call for the MultiAssetCombinatorialPurgedKFold class.
- Parameters:
-
-
X – (pd.DataFrame) Samples dataset that is to be split.
-
y – (pd.Series) Deprecated parameter, sample ranking series.
-
groups – (pd.Series) Deprecated parameter, using samples_info_sets as groups.
-
- Returns:
-
(tuple) [train list of sample indices, and test list of sample indices].
Example
>>> import pandas as pd
>>> import numpy as np
>>> from sklearn.ensemble import RandomForestClassifier
>>> from mlfinlab.cross_validation.cross_validation import ml_cross_val_score
>>> from mlfinlab.cross_validation.combinatorial import CombinatorialPurgedKFold
>>> from mlfinlab.util.generate_dataset import generate_classification_dataset
>>> from mlfinlab.util import generate_dataset
>>> def make_test_data(n_features=40, n_informative=10, n_redundant=10, n_samples=1000):
... x, y = generate_dataset.generate_classification_dataset(
... n_features=n_features,
... n_informative=n_informative,
... n_redundant=n_redundant,
... n_samples=n_samples,
... )
... # We add a time index to both our samples and labels
... dt_index = pd.DatetimeIndex(
... pd.date_range(periods=n_samples, freq="1min", end=pd.Timestamp.today()).round(
... "S"
... )
... )
... x.index = dt_index
... y.index = dt_index
... # We add equal weight as w and t1 as the string form of the timestamp index
... y = pd.DataFrame(y)
... y["t1"] = y.index
... y.rename(columns={0: "bin"}, inplace=True)
... return x, y
...
>>> x, y = make_test_data(n_features=10, n_informative=5, n_redundant=0, n_samples=100)
>>> cv_gen = CombinatorialPurgedKFold(n_splits=3, n_test_splits=2, samples_info_sets=y.t1)
>>> clf = RandomForestClassifier()
>>> # Calculate cross-validation score
>>> print(
... ml_cross_val_score(classifier=clf, X=x, y=y.bin, cv_gen=cv_gen, require_proba=True)
... )
[...]
>>> # Backtesting
>>> backtest_paths = cv_gen.generate_cpcv_backtest_paths_models(model=clf, X=x, y=y.bin)
>>> len(backtest_paths)
2
>>> # Generate historical/backtest probability predictions for a path.
>>> backtest_path_models = backtest_paths[1]
>>> predictions = pd.DataFrame(index=x.index, columns=["proba"])
>>> for model_dict in backtest_path_models:
... # Time index for which we should use particular fit model.
... timestamp_idx = list(model_dict.keys())[0]
... # A model for a particular time index.
... model = list(model_dict.values())[0]
... features_subset = x.loc[timestamp_idx.split("_")[0] : timestamp_idx.split("_")[1]]
... model_probas = model.predict_proba(features_subset)
... proba = pd.Series(index=features_subset.index, data=model_probas[:, 1])
...
>>> predictions["proba"] = proba.copy()
>>> predictions
proba...
Presentation Slides

Note
These slides are a collection of lectures so you need to do a bit of scrolling to find the correct sections.
pg 14-18: CV in Finance
pg 30-34: Hyper-parameter Tuning with CV
pg 122-126: Cross-Validation