Note
The following implementations and documentation, closely follows the lecture notes from Cornell University, by Marcos Lopez de Prado: Codependence (Presentation Slides).
Correlation-Based Metrics
Note
Underlying Literature
The following sources elaborate extensively on the topic:
-
Codependence (Presentation Slides) by Marcos Lopez de Prado.
-
Measuring and testing dependence by correlation of distances by Székely, G.J., Rizzo, M.L. and Bakirov, N.K.
-
Introducing the discussion paper by Székely and Rizzo by Michael A. Newton.
-
Building Diversified Portfolios that Outperform Out-of-Sample by Marcos Lopez de Prado.
-
Kullback-Leibler distance as a measure of the information filtered from multivariate data. by Tumminello, M., Lillo, F. and Mantegna, R.N.
Distance Correlation
Distance correlation can capture not only linear association but also non-linear variable dependencies which Pearson correlation can not. It was introduced in 2005 by Gábor J. Szekely and is described in the work “Measuring and testing independence by correlation of distances”. It is calculated as:
Where \(dCov[X, Y]\) can be interpreted as the average Hadamard product of the doubly-centered Euclidean distance matrices of \(X, Y\). (Cornell lecture slides, p.7)
Values of distance correlation fall in the range:
Distance correlation is equal to zero if and only if the two variables are independent (in contrast to Pearson correlation that can be zero even if the variables are dependant).
As shown in the figure below, distance correlation captures the nonlinear relationship.

The numbers in the first line are Pearson correlation values and the values in the second line are Distance correlation values. This figure is from “Introducing the discussion paper by Székely and Rizzo” by Michale A. Newton. It provides a great overview for readers.
Implementation
- distance_correlation(x: array, y: array) float
-
Returns distance correlation between two vectors. Distance correlation captures both linear and non-linear dependencies.
Formula used for calculation:
Distance_Corr[X, Y] = dCov[X, Y] / (dCov[X, X] * dCov[Y, Y])^(1/2)
dCov[X, Y] is the average Hadamard product of the doubly-centered Euclidean distance matrices of X, Y.
Read Cornell lecture notes for more information about distance correlation: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3512994&download=yes.
- Parameters:
-
-
x – (np.array/pd.Series) X vector.
-
y – (np.array/pd.Series) Y vector.
-
- Returns:
-
(float) Distance correlation coefficient.
Standard Angular Distance
Angular distance is a slight modification of the Pearson correlation coefficient which satisfies all distance metric conditions. This measure is known as the angular distance because when we use covariance as an inner product, we can interpret correlation as \(cos\theta\).
A proof that angular distance is a true metric can be found in the work by Lopez de Prado Building Diversified Portfolios that Outperform Out-of-Sample:
“Angular distance is a linear multiple of the Euclidean distance between the vectors \(\{X, Y\}\) after z-standardization, hence it inherits the true-metric properties of the Euclidean distance.”
According to Lopez de Prado:
“The [standard angular distance] metric deems more distant two random variables with negative correlation than two random variables with positive correlation”.
“This property makes sense in many applications. For example, we may wish to build a long-only portfolio, where holdings in negative-correlated securities can only offset risk, and therefore should be treated as different for diversification purposes”.
Formula used to calculate standard angular distance:
where \(\rho[X,Y]\) is Pearson correlation between the vectors \(\{X, Y\}\) .
Values of standard angular distance fall in the range:
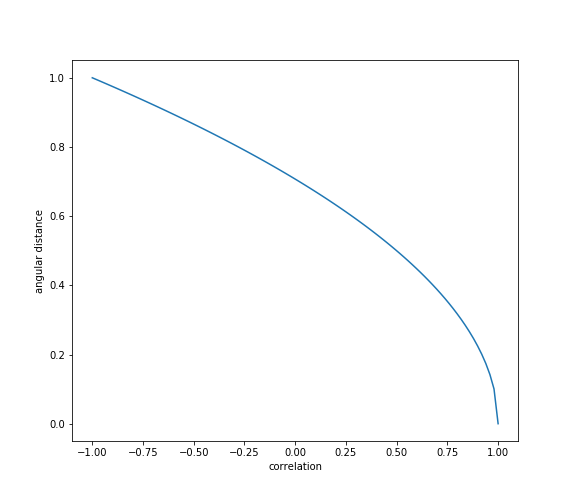
The angular distance satisfies all the conditions of a true metric, (Lopez de Prado, 2020.)
Implementation
- angular_distance(x: array, y: array) float
-
Returns angular distance between two vectors. Angular distance is a slight modification of Pearson correlation which satisfies metric conditions.
Formula used for calculation:
Ang_Distance = (1/2 * (1 - Corr))^(1/2)
Read Cornell lecture notes for more information about angular distance: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3512994&download=yes.
- Parameters:
-
-
x – (np.array/pd.Series) X vector.
-
y – (np.array/pd.Series) Y vector.
-
- Returns:
-
(float) Angular distance.
Absolute Angular Distance
This modification of angular distance uses an absolute value of Pearson correlation in the formula.
This property assigns small distance to elements that have a high negative correlation. According to Lopez de Prado, this is useful because “in long-short portfolios, we often prefer to consider highly negatively-correlated securities as similar, because the position sign can override the sign of the correlation”.
Formula used to calculate absolute angular distance:
where \(\rho[X,Y]\) is Pearson correlation between the vectors \(\{X, Y\}\) .
Values of absolute angular distance fall in the range:
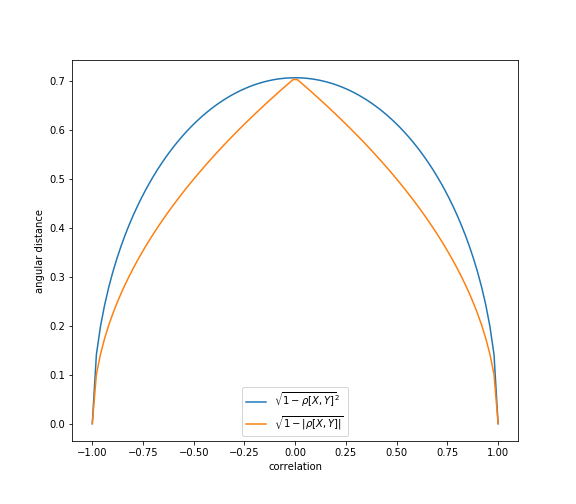
In some financial applications, it makes more sense to apply a modified definition of angular distance, such that the sign of the correlation is ignored, (Lopez de Prado, 2020)
Implementation
- absolute_angular_distance(x: array, y: array) float
-
Returns absolute angular distance between two vectors. It is a modification of angular distance where the absolute value of the Pearson correlation coefficient is used.
Formula used for calculation:
Abs_Ang_Distance = (1/2 * (1 - abs(Corr)))^(1/2)
Read Cornell lecture notes for more information about absolute angular distance: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3512994&download=yes.
- Parameters:
-
-
x – (np.array/pd.Series) X vector.
-
y – (np.array/pd.Series) Y vector.
-
- Returns:
-
(float) Absolute angular distance.
Squared Angular Distance
Squared angular distance uses the squared value of Pearson correlation in the formula and has similar properties to absolute angular distance. The only difference is that a higher distance is assigned to the elements that have a small absolute correlation.
Formula used to calculate squared angular distance:
where \(\rho[X,Y]\) is Pearson correlation between the vectors \(\{X, Y\}\) .
Values of squared angular distance fall in the range:
Implementation
- squared_angular_distance(x: array, y: array) float
-
Returns squared angular distance between two vectors. It is a modification of angular distance where the square of Pearson correlation coefficient is used.
Formula used for calculation:
Squared_Ang_Distance = (1/2 * (1 - (Corr)^2))^(1/2)
Read Cornell lecture notes for more information about squared angular distance: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3512994&download=yes.
- Parameters:
-
-
x – (np.array/pd.Series) X vector.
-
y – (np.array/pd.Series) Y vector.
-
- Returns:
-
(float) Squared angular distance.
Kullback-Leibler Distance
The Kullback-Leibler distance is a measure of distance between two probability densities, say p and q, which is defined as
Where \(E_p[.]\) indicates the expectation value with respect to the probability density \(p\). Here we consider the Kullback-Leibler distance between multivariate Gaussian random variables (aka. Correlation matrices).
Given two positive definite correlation matrices \(C_1\) and \(C_2\) associated with random variable \(X\), we can compute their probability density functions to \(P(C_1,X)\) and \(P(C_1,X)\) resulting in the following formula
where \(n\) is the dimension of the space spanned by \(X\), and \(|C|\) indicates the determinant of \(C\)
The Kullback-Leibler distance can be used to measure the stability of filtering/de-noising procedures with respect to statistical uncertainty.
Tip
It is worth noting that the Kullback-Leibler distance takes naturally into account the statistical nature of correlation matrices which is uncommon with other measures of distance between matrices such as the Frobenius distance which is based on the iso-morphism between the matrices space and the vectors space. For more information on using the Kullback-Leibler distance to measure the statistical uncertainty of correlation matrices check out Michele Tumminello’s research paper.
Implementation
- kullback_leibler_distance(corr_a, corr_b)
-
Returns the Kullback-Leibler distance between two correlation matrices, all elements must be positive.
Formula used for calculation:
kullback_leibler_distance[X, Y] = 0.5 * ( Log( det(Y) / det(X) ) + tr((Y ^ -1).X - n )
Where n is the dimension space spanned by X.
Read Don H. Johnson’s research paper for more information on Kullback-Leibler distance: https://scholarship.rice.edu/bitstream/handle/1911/19969/Joh2001Mar1Symmetrizi.PDF
- Parameters:
-
-
corr_a – (np.array/pd.Series/pd.DataFrame) Numpy array of the first correlation matrix.
-
corr_b – (np.array/pd.Series/pd.DataFrame) Numpy array of the second correlation matrix.
-
- Returns:
-
(np.float64) the Kullback-Leibler distance between the two matrices.
Norm Distance
A Norm is a function that takes a random variable and returns a value(Norm Distance) that satisfies certain properties pertaining to scalability and additivity.
The \(L\) norms are the most common type of norms. They use the same logic behind the SRSS (Square Root of the Sum of Squares)
where \(r\) is a positive integer. The Euclidean norm is by far the most commonly used norm on multi-dimensional variables with \(r = 2\) which makes the Euclidean norm an \(L^2\) type norm.
Implementation
- norm_distance(matrix_a, matrix_b, r_val=2)
-
Returns the normalized distance between two matrices.
This function is a wrap for numpy’s linear algebra method (numpy.linalg.norm). Link to documentation: https://numpy.org/doc/stable/reference/generated/numpy.linalg.norm.html.
Formula used to normalize matrix:
norm_distance[X, Y] = sum( abs(X - Y) ^ r ) ^ 1/r
Where r is a parameter. r=1 City block(L1 norm), r=2 Euclidean distance (L2 norm), r=inf Supermum (L_inf norm). For values of r < 1, the result is not really a mathematical ‘norm’.
- Parameters:
-
-
matrix_a – (np.array/pd.Series/pd.DataFrame) Array of the first matrix.
-
matrix_b – (np.array/pd.Series/pd.DataFrame) Array of the second matrix.
-
r_val – (int/str) The r value of the normalization formula. (
2by default, Any Integer)
-
- Returns:
-
(float) The Euclidean distance between the two matrices.
Examples
The following examples show how the described above correlation-based metrics can be used on real data:
import pandas as pd
import numpy as np
# Import MlFinLab tools
from mlfinlab.codependence.correlation import (
distance_correlation,
angular_distance,
absolute_angular_distance,
squared_angular_distance,
kullback_leibler_distance,
norm_distance,
)
# Pull data from example data on Github
url = "https://raw.githubusercontent.com/hudson-and-thames/example-data/main/stock_prices.csv"
asset_returns = pd.read_csv(url, index_col="Date").pct_change().dropna()
# Calculate distance correlation between chosen assets
distance_corr = distance_correlation(asset_returns["SPY"], asset_returns["TLT"])
# Calculate angular distance between chosen assets
angular_dist = angular_distance(asset_returns["SPY"], asset_returns["TLT"])
# Calculate absolute angular distance between chosen assets
abs_angular_dist = absolute_angular_distance(asset_returns["SPY"], asset_returns["TLT"])
# Calculate squared angular distance between chosen assets
sqr_angular_dist = squared_angular_distance(asset_returns["SPY"], asset_returns["TLT"])
# Creates correlation matrices of the returns DataFrame at different time frames
corr_13 = np.corrcoef(asset_returns["2013":"2014"], rowvar=False)
corr_14 = np.corrcoef(asset_returns["2014":"2015"], rowvar=False)
# Calculate the Kullback-Leibler distance between two correlation matrices
kl_dist = kullback_leibler_distance(corr_13, corr_14)
# Calculate the norm distance between two correlation matrices
norm_dist = norm_distance(corr_13, corr_14)
print(
{
"Distance Correlation": distance_corr,
"Angular Distance": angular_dist,
"Absolute Angular Distance": abs_angular_dist,
"Squared Angular Distance": sqr_angular_dist,
"Kullback-Leibler Distance": kl_dist,
"Norm Distance": norm_dist,
}
)
# Results
# {'Distance Correlation': 0.43462011036186643, 'Angular Distance': 0.8546360415920284,
# 'Absolute Angular Distance': 0.5192275381871695, 'Squared Angular Distance': 0.6275580714658525,
# 'Kullback-Leibler Distance': 2.4360342313867633, 'Norm Distance': 3.3215716791492302}
Presentation Slides

